
Azureでログを監視して、特定の条件を満たしたときに通知を行うことが良くあります。この時、監視間隔や通知の頻度について設計することが重要です。少なすぎるとインシデントの対処が遅れ、多すぎるとアラート疲れの原因になります。
ログアラートルールの設定には、「集計の粒度」、「評価の頻度」、「評価期間」といった似たような言葉が存在します。5分毎に監視を行いエラーが発生したら毎回通知を行いたい、5分毎に監視を行い過去15分間で2回エラーが発生したら通知を行いたい、など様々な要件があります。この時、3つの設定値はどんな値を指定すればいいのでしょうか。
私自身は理解が曖昧なままなんとなくで設定していたところがあります。そこで、アラートルールの設定について、主に間隔・期間に関するものを中心に調べて理解していきます。
前提・用語
今回は「ログアラートルール」についてみていきます。他にもメトリクスアラートルールやPrometheusアラートルールなどがあります。それぞれ設定内容が異なりますので、今回はログアラートであることを念頭に読み進めてください。
監視用のクエリは以下のものを用意しました。Azure Functionsで作成したAPIを実行し、レスポンスが200以外の場合にエラーとみなします。このクエリ結果で出力される行数がエラー数となります。
requests | where resultCode != 200 |project timestamp,id,name,resultCode
これから、間隔や期間の設定に関する用語が複数登場します。日本語の場合はドキュメントやAzure Portal上で使われる用語が異なる場合があります。そのため本ブログでは、日本語(Azure Portal)バージョンで統一します。また、参考としてマッピング表を記載しますので、必要に応じて読み替えてください。
| 日本語(Azure Portal) | 日本語(ドキュメント) | 英語 |
| 集計の粒度 | 集計の細分性 | Aggregation granularity |
| 評価の頻度 | 評価の頻度 | Frequency of evaluation |
| 評価期間 | 評価期間 | Evaluation period |
集計の粒度と評価の頻度について
まずはベースとなる集計の粒度と評価の頻度を見ていきます。この2つは必ず設定が必要になります。3つ目の評価期間については次の章で確認します。
集計の粒度は、指定した間隔でデータを丸めます。1分毎にデータがある場合に、集計の粒度を5分に設定したとします。すると、5分毎にデータが合計(カウント)されます。この5分毎のデータに対して評価の頻度で指定した間隔で評価がなされます。実際の画面ですと以下の画像に示した設定です。今回は単純にログのクエリ結果をもとエラー数を評価するアラートルールを想定していますので、メジャーはテーブルの行、集計の種類はカウントになります。CPU使用率など数値の場合は、集計の種類にはカウントだけでなく平均などの選択肢もあります。
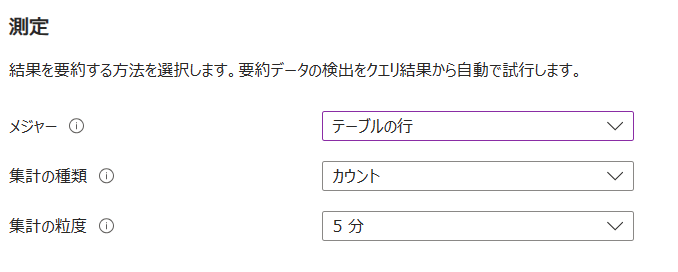
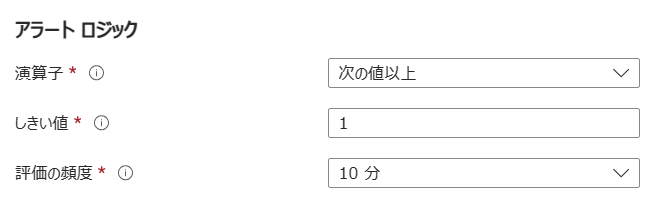
評価の頻度は、アラートルールの実行間隔を指定します。監視間隔ですね。10分毎に監視を行いたいのであれば10を指定します。以下のように設定することで、10分毎に冒頭に記載したクエリが実行され、レスポンスコード200以外のレスポンス(エラー)が1つ以上あった場合に条件を満たします。
では、集約の粒度と評価の期間を3パターンに分けて、実際どのようにアラートが発生するか見ていきましょう。
「集約の粒度」:5分、「評価の頻度」:5分
データは5分毎に合計され、そのデータを5分毎に評価します。下記の例では3分毎にエラーを1件発生させた場合のアラート発生状況をまとめた図になります。アラート発生のしきい値は2以上とします。
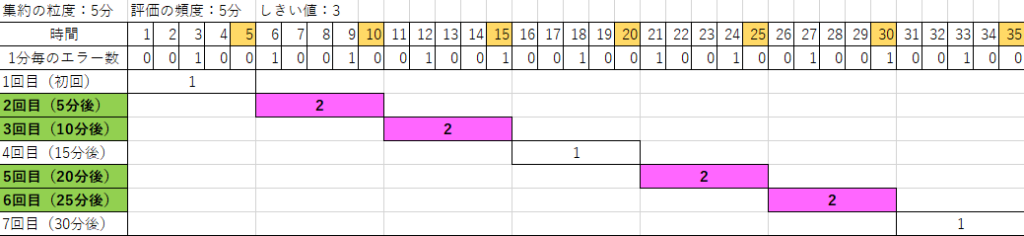
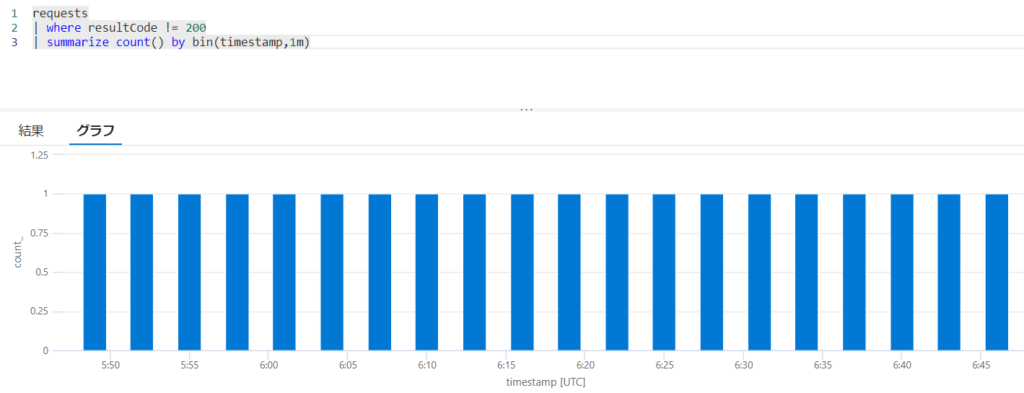
3分毎にエラーを発生させ、5分毎に集約しているため、5分間のエラー数が1回か2回のどちらかになります。そして2回エラーが発生したときにアラートが発生します(ピンク色のセル)。実際にAzure上で実行してみた結果を見てみましょう。20時~21時の間で3分後ごとにエラーを発生させています。
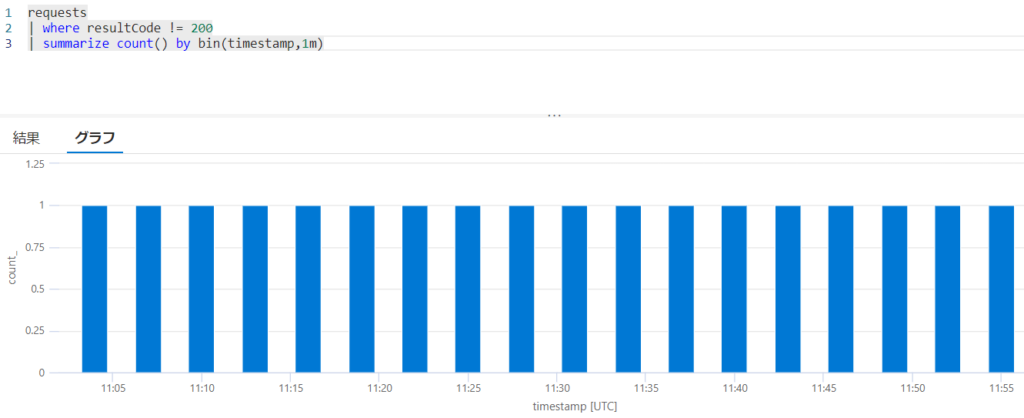
アラートの発生状況を見てみます。以下のように、想定通り、5分もしくは10分おきにアラートが発生しています。20時14分や20時29分においてアラートが発生していません。これは過去5分間のエラー数が1件だけだったためです。

「集約の粒度」:5分、「評価の頻度」:10分
データは5分後に合計され、そのデータを10分毎に評価します。エラーを3分おきに発生させ、しきい値を2以上としたときのアラートの発生状況は以下のようになります。評価の頻度が集約の粒度より大きい場合は、評価に頻度内のどこかのポイントでしきい値に達すればアラートが発生します。評価の頻度10分の中に5分毎に集約された結果が2つ含まれますので、どちらかでエラー数が2以上であればよいのです。そのため、以下のように10分毎に毎回アラートが発生します。私は最初勘違いしていましたが、直近の5分間だけを評価するのではありません。

実際にAzureで試した結果を確認しましょう。以下の通り20時21分にアラートが発生しています。下記画像だけではわかりませんが、正確には20時21分20秒です。「View query results」のリンクをクリックすると、20時11分20秒~20時21分20秒でカスタム時間が設定された状態の結果を確認できます。
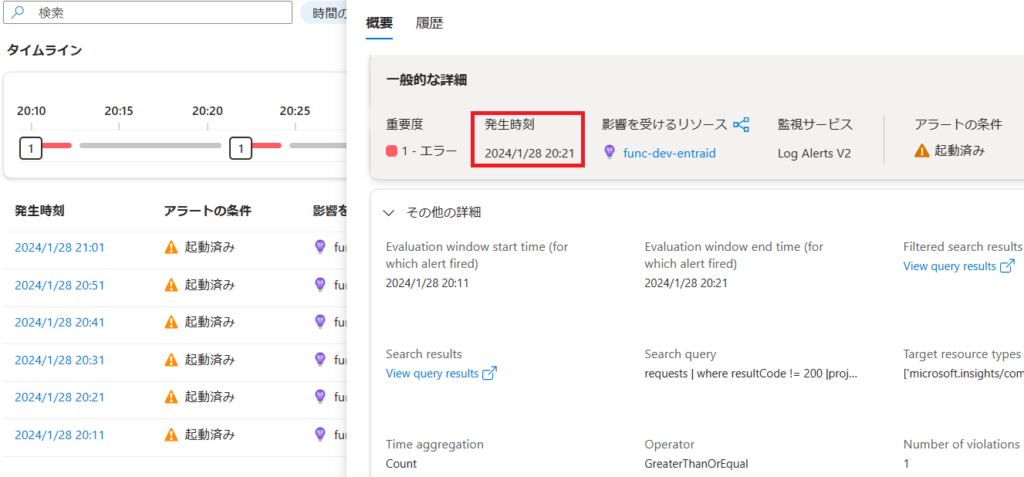
そして、この期間のエラー発生数は以下の3回です。直近5分間(20時16分20秒~20時21分20秒)だとエラーは20時19分2秒の1回だけです。しかし実際は前半の5分間と直近の5分間の両方が評価され、前半の5分間でエラー数2以上を満たしているので、アラートが発生しています。
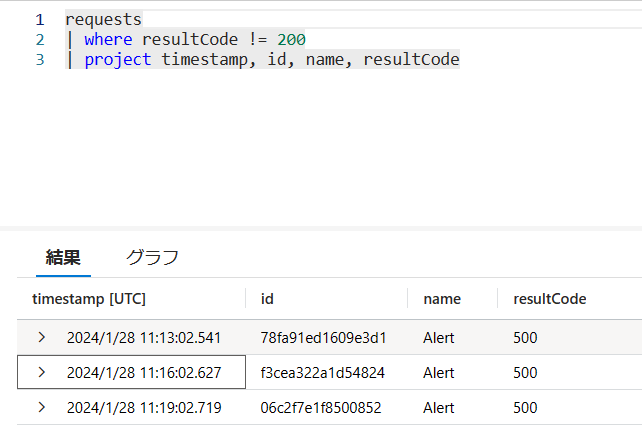
ちなみにこの動作はデフォルトです。詳細設定オプションを変更することで、この動作を変えることができます。詳細設定については次の章で見ていきます。
「集約の粒度」:5分、「評価の頻度」:1分
今回は、2分毎にエラーを1回発生させた場合の例で考えてみます。エラー数の閾値は3です。5分ごとに集計するとカウントが2になるパターンと3になるパターンが交互に出現します。そのため2分おきに条件を満たします。
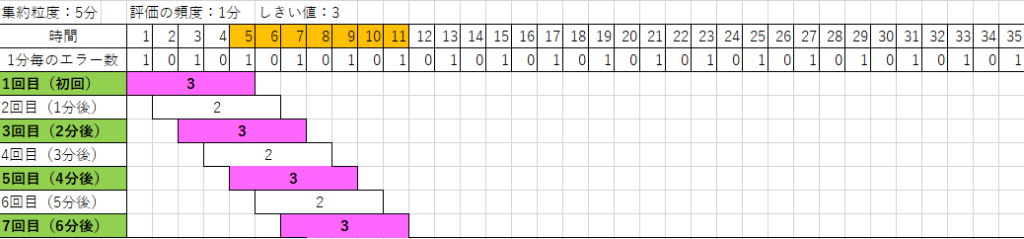
実際の結果も見てみましょう。まずはエラー数ですが、以下の通り2分おきに1つ発生しています。
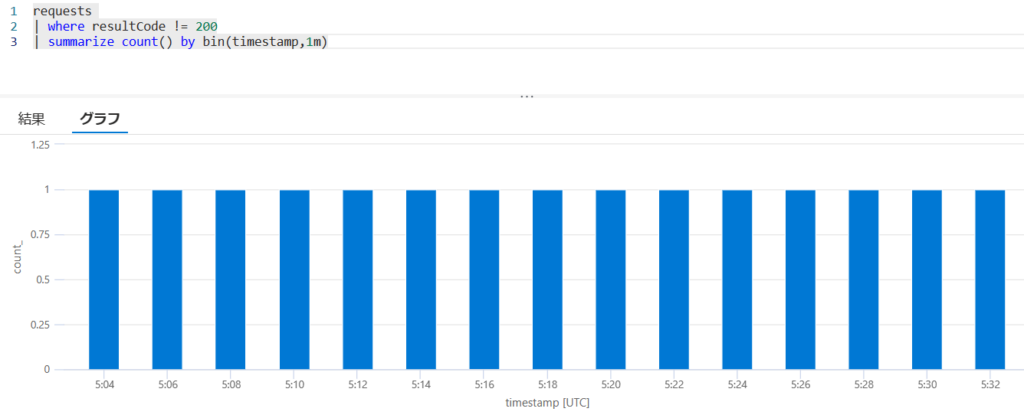
アラートの履歴を見てみます。一部ずれている個所はありますが、概ね予想通り2分毎にアラートが発生しています。
詳細設定を含めたパターン
アラートルールには、詳細設定として「違反の数」と「評価期間」を指定できます。指定しないときはデフォルトで違反の数は1、評価期間は評価の頻度と等しくなっていると思います。

「集約の粒度を5分、評価の頻度を5分」に指定した場合は、5分毎にエラー数が評価されアラートが発生するかどうかが決まっていました。この時、詳細設定の違反の数を2、評価期間を10分にしたと仮定します。この場合、まず最初の5分間でエラー数がしきい値に達したときにはまだアラートは発生しません。次の5分間でもエラー数がしきい値に達するとようやくアラートが発生します。つまり2回連続違反するとアラートが発生します。
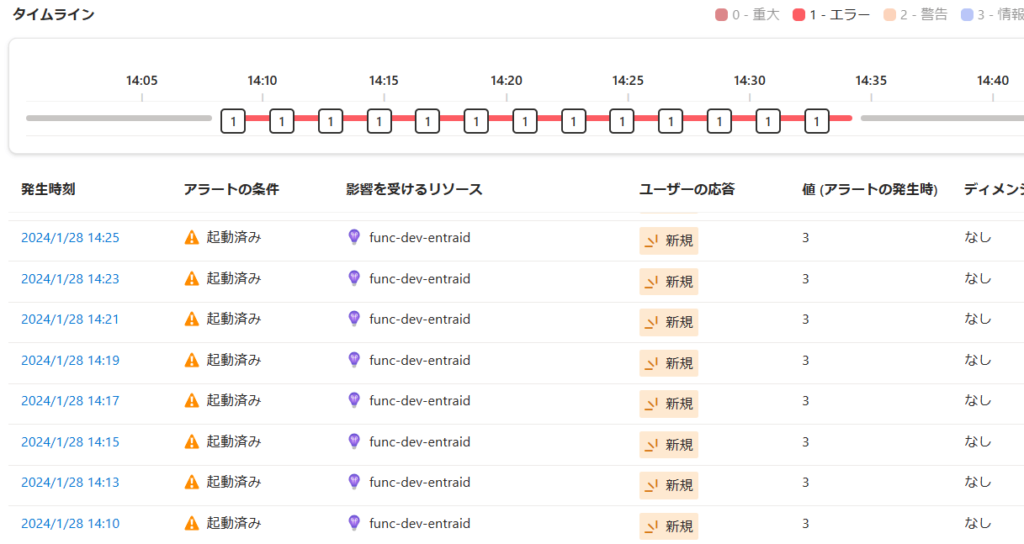
「「集約の粒度」:5分、「評価の頻度」:5分」の時と同じように、3分毎のエラーを発生させました。
以下のように2回連続違反しないとエラーは発生しないので、厳しい条件になります。
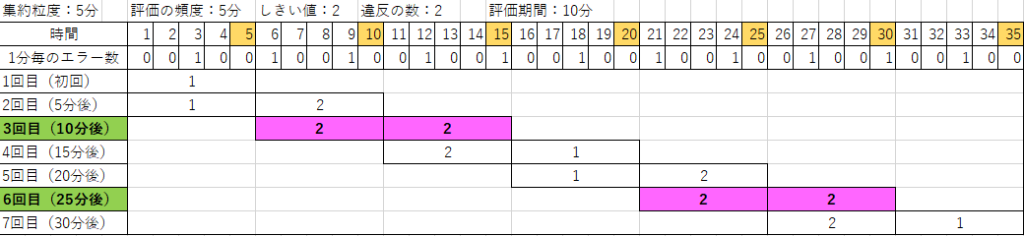
実際にアラート発生状況を見てみると、1時間中3回しか発生していませんでした。5分間でエラー数が2以上になった回数は3回以上ありますが、「5分でエラー2回」が連続したのは下記の3つの時刻だけということです。
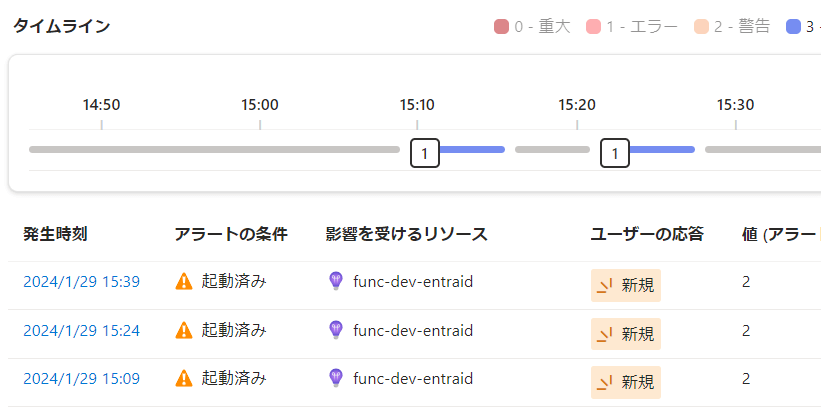
続いて、違反の数を2、評価期間を15分にしてみます。この時は15分(3回評価のタイミングがある)のうち2回違反していればアラートが発生します。先ほどより条件が緩くなります。3分毎に1回エラーを発生させているため、計算上必ず3回のうちどこか2回で違反します。つまり監視開始して15分後から5分毎に毎回アラートが発生することになります。
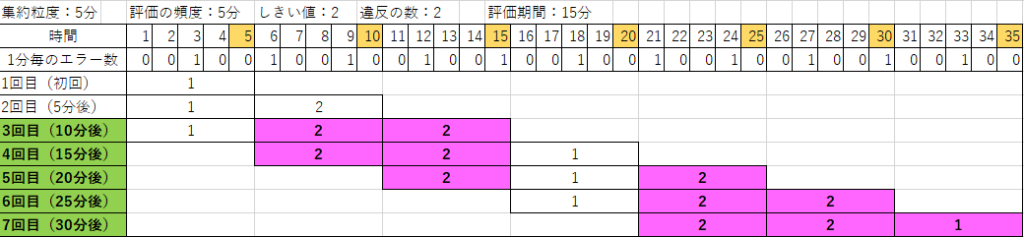
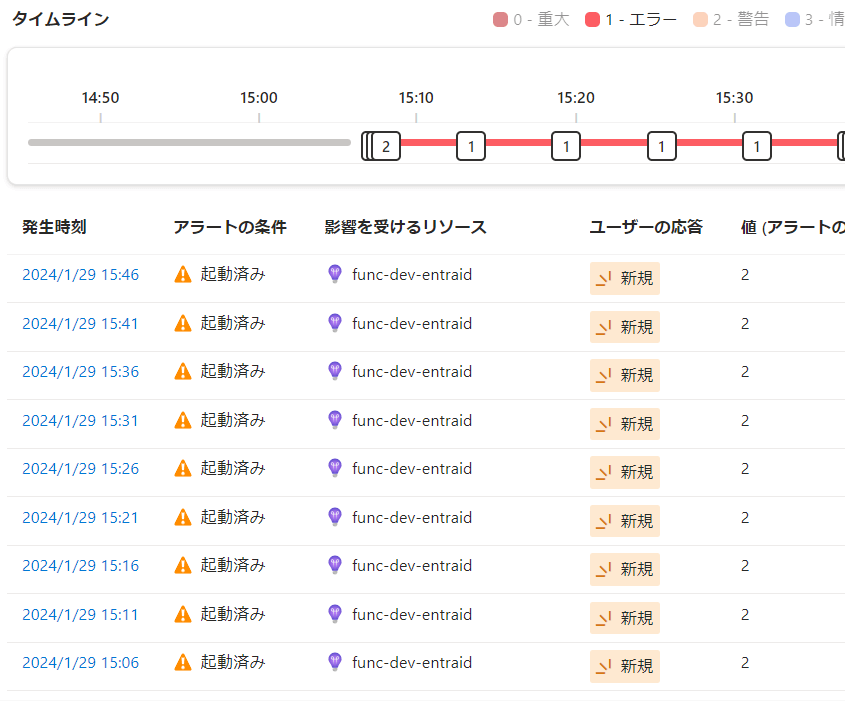
実際のアラート発生状況を見ても、初回の15時6分以降、5分毎に毎回アラートが発生しています。
最後に
アラートルールには、似たような設定項目が複数あるので最初は混乱します。少しでも理解の助けになれば幸いです。
コメント