
Databricksでノートブックなどを開発する際は、ブラウザ上でも開発できます。しかし、開発するならVSCodeなどのツールを用いてローカル開発環境で行うことが多いと思います。ただし、ローカルで開発するとなると諸々準備作業が多くて面倒です。そこでプログラミング自体はローカルで行いつつ、実行環境はAzure Databricksのクラスターを利用することで、開発に必要な準備作業を削減してスムーズに開発を行うことができます。
ローカル開発環境からAzure上のDatabricksクラスターに接続する方法は複数ありますが、今回は「Databricks Power Tool拡張機能」を用いた簡単な方法で接続してみます。
環境
| Databricks Runtime のバージョン | 13.3 |
| Python(Databricks) | 3.10 |
| OS(ローカル) | Windows 11 |
Azure Databricksの作成
まずはDatabricksワークスペースを作成します。Pricing Tierは14日間利用できるPremiumのトライアルを選択しました。それ以外はデフォルトのままで大丈夫です。ワークスペースの作成自体は設定項目も少なくシンプルです。
クラスターの作成
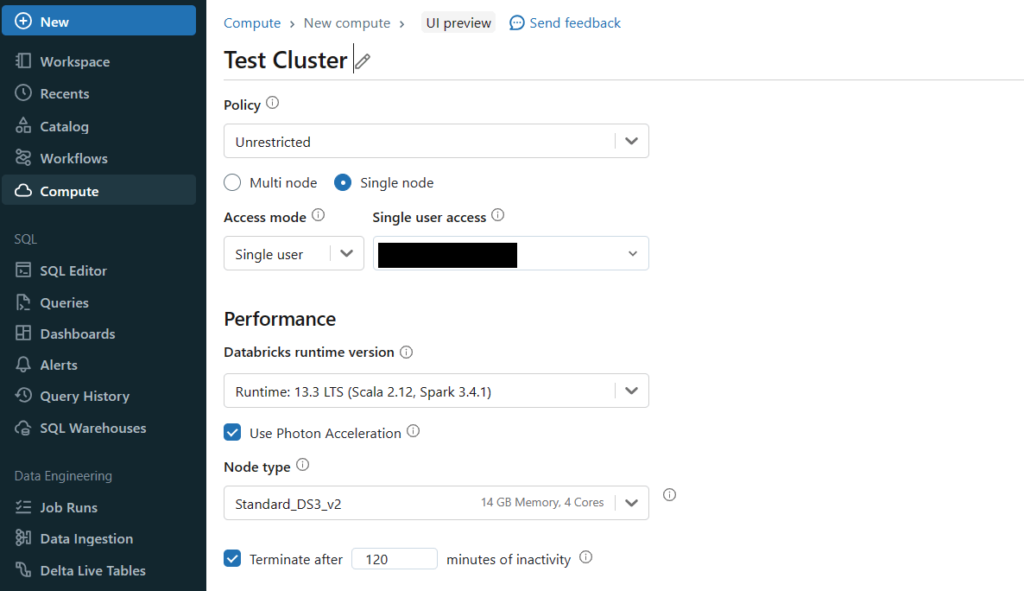
続いて実行環境であるクラスターを作成します。ノートブックなどはこの環境上で実行されます。またローカルのVSCodeでの実行の際も、ここで作成するクラスターに接続してノートブックを実行します。
クラスターのアクセスモードをシングルユーザーにしていますが、特に指定はありません。それ以外はデフォルト設定のまま作成します。
サンプルデータの準備
簡単なデータを用意します。この後のノートブックではこのcsvを読み取り、そのデータを表示する処理を記載します。
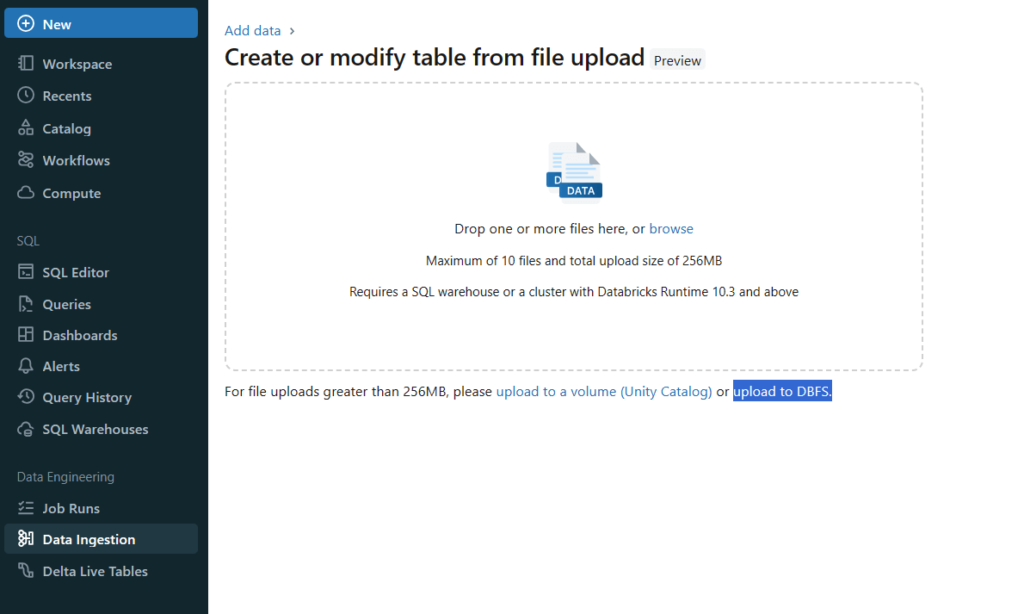
ワークスペースの「Data Ingestion」> 「Create or modify table」>「Upload to DBFS」の順に選択してcsvファイルをアップロードします。
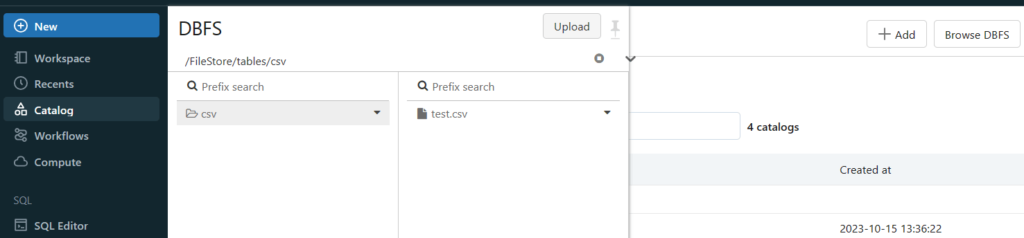
アップロードしたファイルは「Catalog」の「Browse DBFS」から確認できます。できない場合は管理者設定のワークスペース設定から「DBFS File Browser」を有効にします。
ノートブックの作成
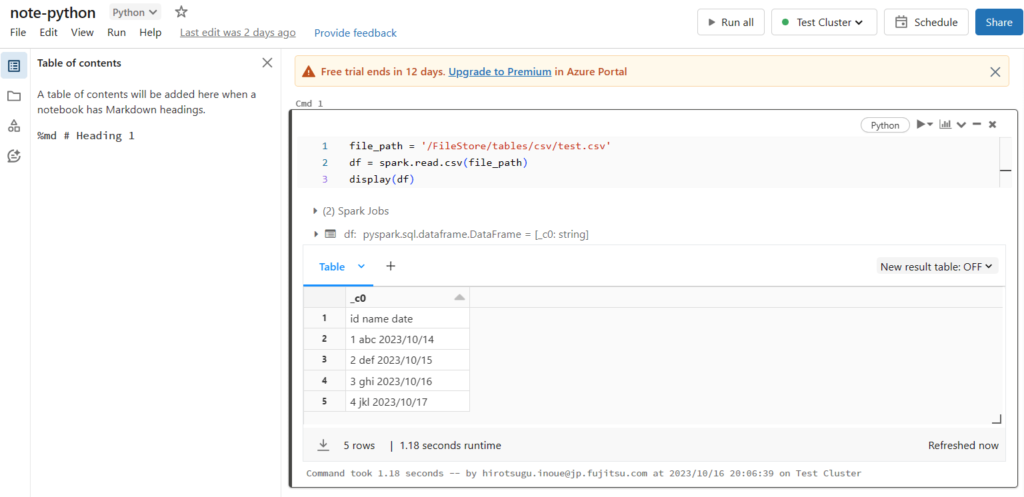
ノートブックを作成して、csvのデータを読み取ってみます。内容は以下の3行だけのシンプルなものです。
file_path = '/FileStore/tables/csv/test.csv'
df = spark.read.csv(file_path)
display(df)実行してみると、以下のようにcsvのデータが出力されています。spark変数などの構成は行っていませんが、Databricksクラスターにアタッチして実行すると自動で構成してくれます。
ちなみにノートブックからもFileタブからDBFSに格納したcsvファイルを確認できます。
ローカル開発環境の設定
つづいてはWindows上のVSCodeからノートブックを作成して、Azure上のDatabricksクラスター経由で実行してみます。
拡張機能のインストール
今回は「Databricks Power Tools」を利用してクラスターに接続します。その他「Databricks」など必要に応じてインストールしてください。
ノートブックの作成
拡張子「ipynb」でノートブックを作成します。コードはAzure上で作成したノートブックと全く同じものです。そのため同じくAzure上にあるcsvファイルを読み取ります。当然ローカル開発環境には記載されたパスは存在しませんが、Azure上のDatabricksクラスターに接続することでcsvファイルにもアクセスできます。
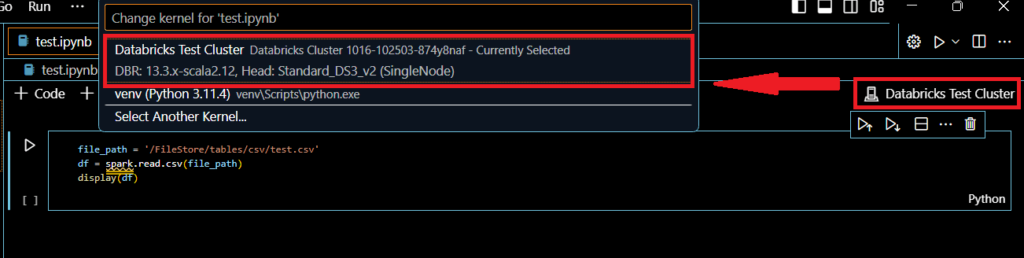
右上にkernelを選択といボタンがありますので、これを押して実行環境を指定します。指定できたら実際に実行してみます。
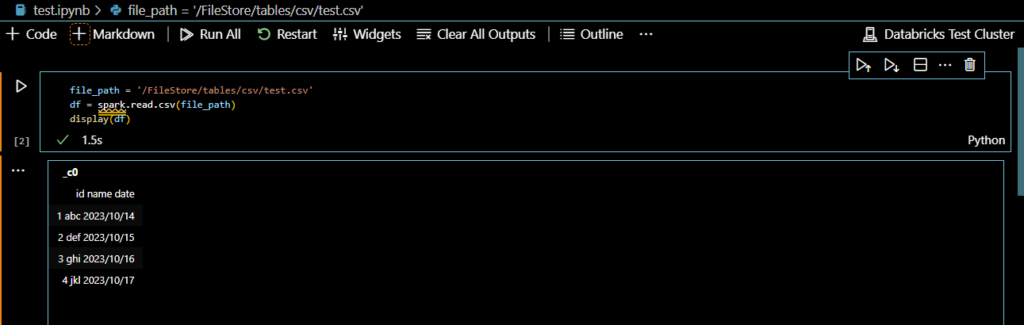
無事Azure上で実行した結果と同じ結果を得ることができました。Azure上にあるファイルも問題なく読み取ることができています。
まとめ
VSCodeの「Databricks Power Tool拡張機能」を利用することで、特別な設定を行うことなく非常に簡単にAzure上のDatabricksクラスターに接続することができました。ローカル開発環境にランタイムを準備したり、SparkコンテキストやSparkセッションを構成する必要もありません。とりあえず簡単に動かしてみたい場合には有効な方法だと思います。
ちなみに今回使用した方法以外に、「Databricks拡張機能」と「Databricks Connect統合」を利用することでもDatabricksクラスターにアタッチできます。さらにデバッグもできるため本格的な開発ではConnect統合を利用した方法がよさそうです。
「Databricks Connect統合」を利用した開発については下記の記事にまとめていますので、よろしければご確認ください。

コメント