
VSCodeの拡張機能(Databricks)の「Databricks Connect統合」を利用することで、ローカル開発環境からAzure Databricksクラスターに接続し、pythonやscalaのコードをデバック実行することができます。
今回はpythonを例に、Databricks Connect統合を試していきます。
環境
Azure
| Databricksワークスペース | Premium(トライアル) |
| Databricks Runtime | 13.3 |
| Python | 3.10.12 |
ローカル環境
| OS | Windows11 |
| VSCode | 1.83.1 |
| Python | 3.10.9 |
Azure準備作業
Azure Databricksワークスペースを作成します。作成自体は簡単なので省略します。ワークスペースを作成したらクラスターを作成するのですが、注意点が3つあります。
- Unity CatalogがAzure Databricksワークスペースに対して有効になっている
- DatabricksクラスターにはDatabricks Runtime 13.0以降がインストールされている(Pythonの場合)
- Databricksクラスターのアクセスモードが「割り当て済み」もしくは「共有済み」である。
以降で順番に見ていきますが、詳細については下記のMSドキュメントを参照してください。

Unity Catalogの有効化
Unity Catalogを有効にすることで、Databricksワークスペース全体でアクセス制御を一元管理できます。また監査やデータ検出の機能などが備えられています。Unity Catalogは以上の機能を持ったガバナンスソリューションです。Unity Catalogについての詳細は下記MSドキュメントを参照してください。
Unity Catalogの有効化についてですが、まずは各種データを管理するメタストアを格納するためのAzure Data Lake Storage Gen2アカウントをDatabricksと同じリージョンに作成します。作成するときは、Premiumパフォーマンスかつ階層名前空間を有効にします。それ以外はデフォルトのままで問題ありません。作成後、メタストア用のコンテナを作成します。ここではコンテナ名を「metastore」としています。
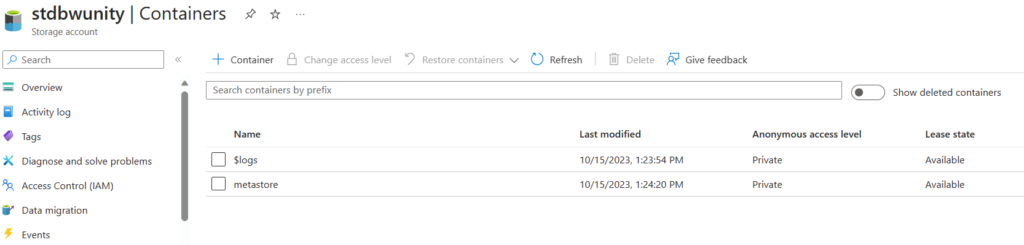
続いて、Databricks用のアクセスコネクタを作成し、ストレージへのアクセス権限を与えます。Unity Catalogはこのアクセスコネクタを利用してストレージのコンテナにアクセスします。
アクセスコネクタ自体の作成は特別な設定はありません。必要な情報(名前やリージョンなど)を入力して作成します。作成時のデフォルトの設定でマネージドIDが有効になっていますので、このマネージドIDに対して先ほど作成したストレージへの「ストレージBLOBデータ共同作成者」ロールを付与します。またアクセスコネクタのリソースIDを後程使用しますのでメモしておきましょう。
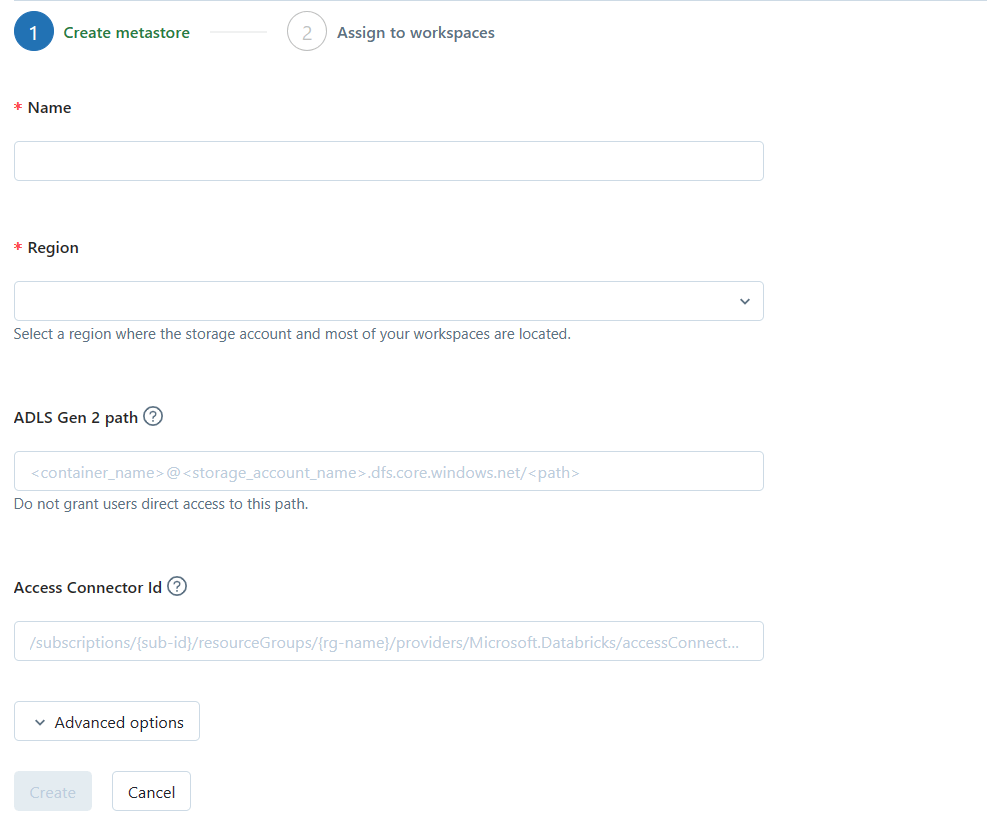
最後にメタストアを作成してDatabricksワークスペースに割り当てます。Databricksワークスペースの右上からManage Accountを選択します。その後、「Data」 > 「create metastore」の順に選択します。

「ADLS Gen 2 path」には「abfss://<コンテナ名@<ストレージアカウント名>.dfs.core.windows.net/」を入力します。「Access Connector Id」には先ほどメモっておいたアクセスコネクタのリソースIDを入力します。
メタストアを作成したら、紐づけたいDatabricksワークスペースを選択してAssignします。Unity Catalogを有効にするかのメッセージが表示されますので有効にして完了です。
クラスターの作成
VSCodeから接続する先のクラスターを作成します。アクセスモードは「Single User」か「Shared」に設定します。そのほかはデフォルトのままで構いませんので、必要に応じて設定してください。ただしランタイムは13.0以上が必要です。
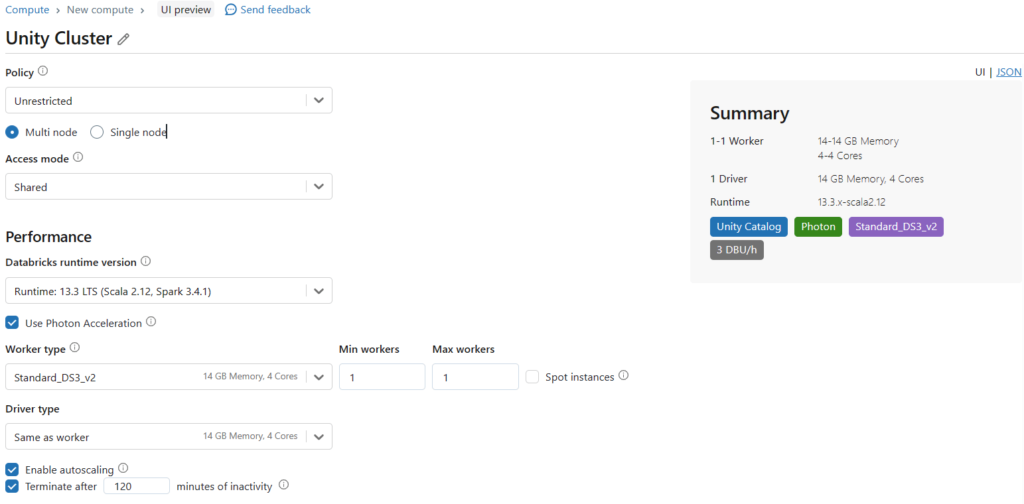
ローカル開発環境の準備
ここからはローカル開発環境の設定を行います。VSCodeやPythonは設定してある前提で進めます。PythonはAzure Databricksクラスターにインストールされているバージョン(メジャー、マイナー)と同じである必要があります。今回はpython 3.10がクラスターにインストールされているので、ローカルでも3.10をインストールします。(3.11でも動作しましたが、基本的にはバージョンは揃えましょう。)
拡張機能のインストールと設定
拡張機能「Databricks」をインストールします。インストールしたらAzureへの認証を行います。私の環境はすでにAzure CLIで認証ができていたためそれを利用しました。認証後はDatabricksのワークスペースのURL(https://adb-xxxxxx.azuredatabricks.net)を求められるので、Azure PortalのDatabrciksの概要からURLをコピーして入力します。
その後、Databricks拡張機能のClusterの歯車マークをクリックして、先ほど作成したクラスターを選択します。下記のように緑のチェックマークが表示されていれば大丈夫です。
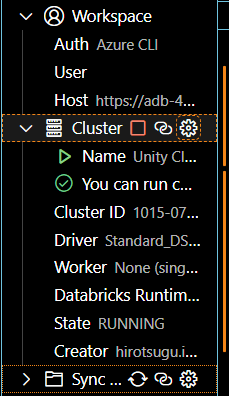
Databricks Connectの設定
ここまでの設定で、VSCodeのステータスバーの左下あたりに「Databricks Connect disabled」と表示されていますので、これをクリックします。もしくはコマンドパレットで「Databricks: Configure autocomplete for Databricks globals」を入力して実行します。python仮想環境を利用する場合は予め仮想環境をactivateしておきます。
プロンプトが表示されるので、それに従い構成していきます。この時、クラスター要件を満たしていない場合、以下のようなエラーメッセージが表示されます。
Databricks Connect requires a Unity Catalog enabled cluster with Access Mode "Single User" or "Shared".
クラスターの要件が問題なければ、databricks-connectモジュールをインストールします。自動で以下のようにモジュールをインストールするコマンドが実行されます。
'c:\code\projetc\venv\Scripts\python.exe' -m pip install 'databricks-connect==13.3.2' --disable-pip-version-check --no-python-version-warning; echo $? > C:\Users\user\AppData\Local\Temp\databricks-vscode-NL2qWB\python-terminal-output.txt
しかし、私の環境では以下のようなエラーが発生しインストールできませんでした。
Unexpected token '-m' in expression or statement.
そこで、先頭の「c:path/python.exe -m」を除いて「pip~」以降のコマンドをコピーして直接実行しました。インストール完了後は以下のようにDatabricks Connect enabledになっていれば接続環境です。

デバック実行
やっと準備が整いましたので、実際にpythonファイルやノートブックをデバック実行してみます。
pythonファイル
まずはpythonファイルです。以下のようにsparkセッションを構成します。コード自体はローカルで実行されますのでsparkセッションの構成が必要になります。ただし、DataFrameの操作などPySparkコードはAzure Databricksクラスターで実行されて、結果がローカルに返却されます。
from databricks.connect import DatabricksSession
spark = DatabricksSession.builder.getOrCreate()
file_path = '/FileStore/tables/csv/test.csv'
df = spark.read.csv(file_path)
df.show()後はいつも通りPythonファイルをデバック実行します。
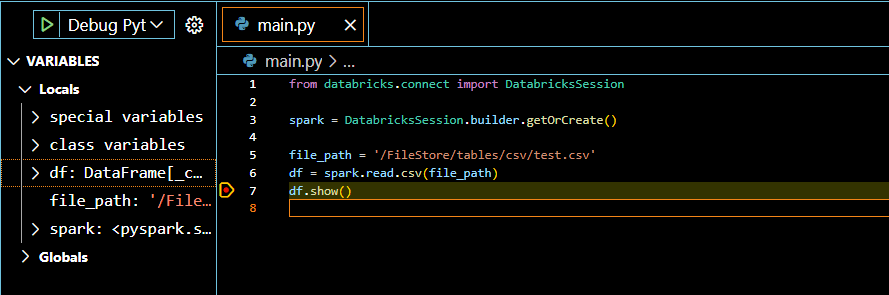
Azure Databricks上のファイルシステム(DBFS)に格納したファイルを読み取っています。実行自体はローカルから行っていますが、Databricksクラスターに接続しているため問題なく読み取れています。
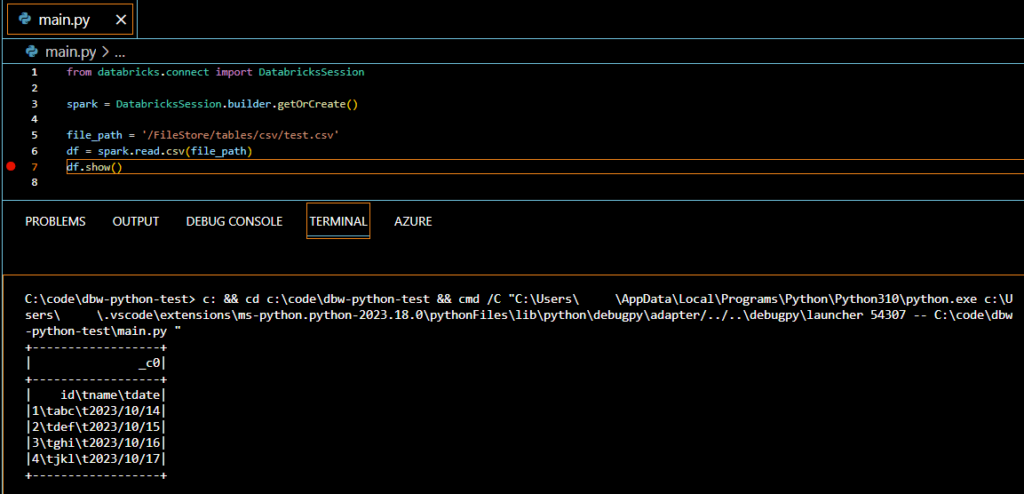
DBFSへのファイルのアップロードに関しては下記の記事を参照してください。

ノートブック
ノートブックでは「Run Next Line」をクリックすることで、1行ごとにデバック実行できます。ノートブックを実行するときに「ipykernelモジュール」が必要なため、なければインストールします。
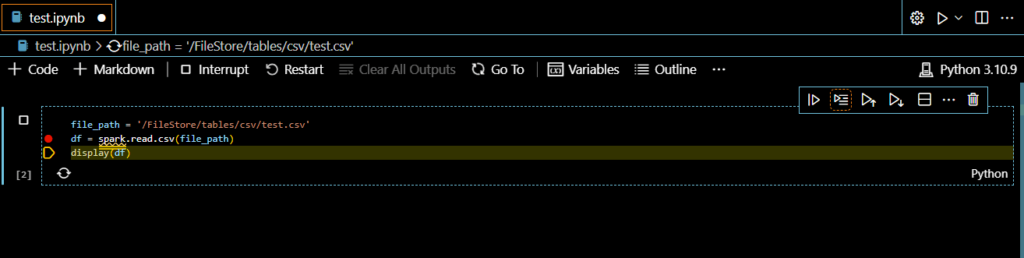
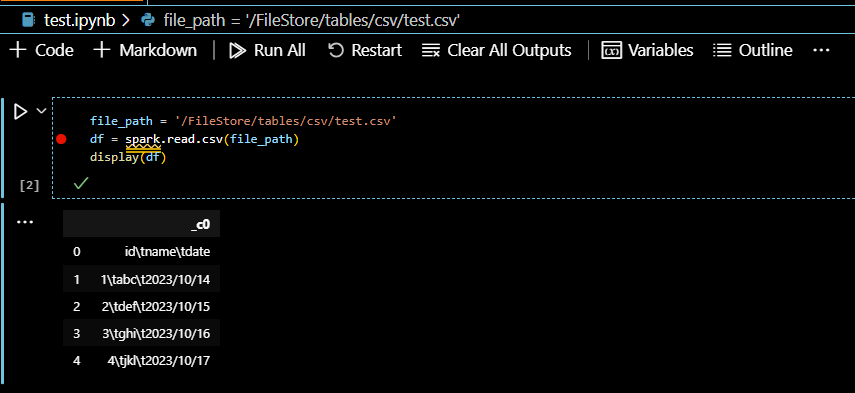
上記を見て分かる通り、ノートブックではsparkセッションやdisplay関数などがあらかじめ構成されているため、自分で構成しなくても実行できます。pythonファイルと同様に、PySparkコードはAzure Databricksクラスターで実行されるため、AzureのDatabricks上に存在するファイルを処理するコードも問題なく実行できています。
まとめ
設定する項目が非常に多くやや大変ではありましたが、無事ローカルからAzure Databricksクラスターに接続してローカルのpythonコードをデバック実行することができました。デプロイ先と同じ環境で開発できるため、デプロイ後の非互換も気にすることなくスムーズに開発できます。
ここまで来たらあとはデプロイを検討したいと思います。Azure Functionsなどと同様にコードをgitにpushするだけで、Azure Databricks上にデプロイできると非常に便利で効率的に開発できます。そのため、次回はデプロイについて調べてまとめていきます。
コメント