
private endpointが有効になっているStorage Accountから、csvファイルを読み取る処理をDabricks上で実装します。この時、デフォルト設定のままDatabricksワークスペースを作成すると、ワークスペースはMicrosoftが管理するVNETに配置されます。しかし、MS管理VNET内には制限がかけられており、基本的に読み取り以外の操作ができません。そのため、private通信を行うための設定ができません。
そこでDatabricks用のカスタムVNETを作成し、この中にDatabricksを作成するように構成します。今回は、このprivateな通信を実現するための方法とその設定手順について紹介します。
結論
事前にDatabricks用のVNETを作成し、Azure Databricks作成時にそのVNETを指定します。その後private endpoint用のVNETとピアリングやDNSゾーンの紐づけを行うことで、DatabricksからStorageにprivateアクセスすることができます。
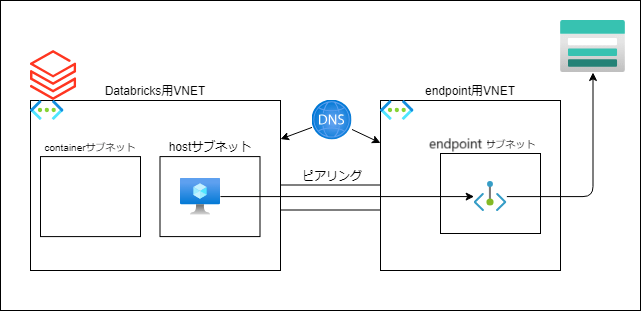
※Databricksクラスターをhostサブネットに描いていますが、実際はcontainerサブネットにもNICが生えています。
事前準備
予めDatabricksワークスペース用とStorage Accountのprivate endpoint用の2つのVNETを作成しておきます。後程この2つのVNETはピアリングしますので、CIDRは被らないようにしておきます。
ここではDatabricksワークスペースを「vnet-databricks」、Storage Accountのprivate endpoint用VNETを「vnet-endpoints」という名前で作成しています。
またStorage AccountにDatabricksから読み取るCSVファイルをアップロードしておきます。Storage Accountは「Azure Data Lake Storage Gen2」として作成しますので、階層型名前空間を有効にしておきます。ネットワーク設定は後程行いますので、現時点ではデフォルト設定のままで問題ありません。
Databricksワークスペースを利用者管理VNETに配置する
Azure Databricksの作成
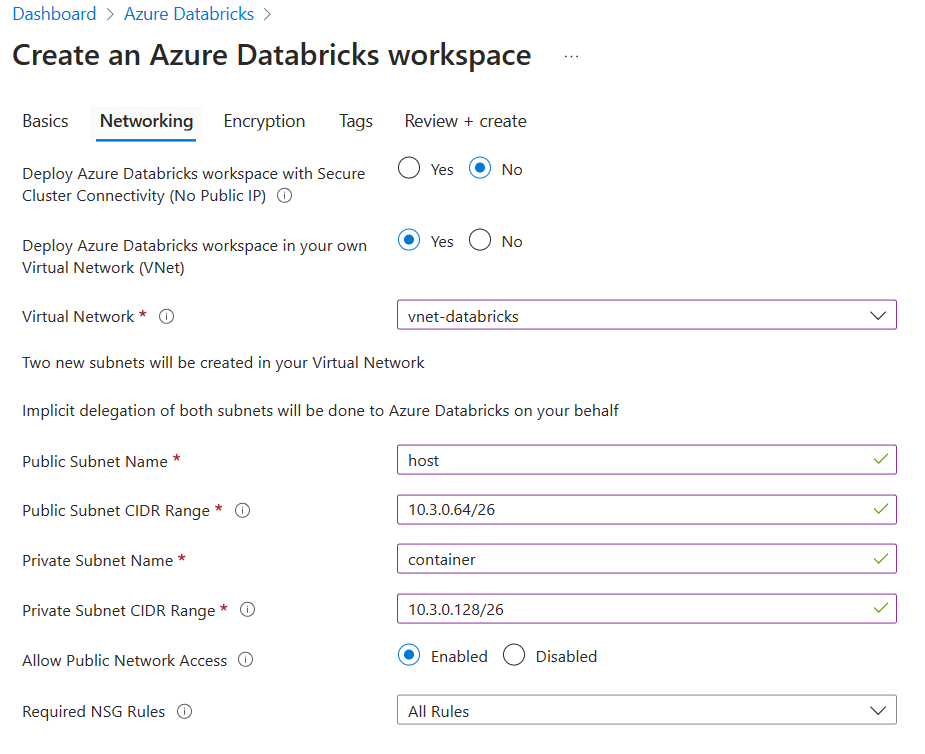
Databricksワークスペースを利用者管理VNETに配置するための設定は、ワークスペース作成時に行います。
「Deploy Azure Databricks workspace in your own Virtual Network (VNet)」をYesにして、VNET情報を入力します。この時2つのサブネットが必要になります。予めサブネットを作成している場合はその名前とCIDRを入力します。作成してない場合でもここで指定した名前とCIDRで作成されます。
そのほかの設定はデフォルトのままで問題ないため、このまま作成します。
Storage Accountのcsvを読み取って表示してみる
最終的にはprivate通信でStorageのcsvファイルを読み取りますが、その前にpublicで問題なく読み取れるか確認しておきます。Databricksワークスペースでノートブックを作成して以下のコードを記載します。ノートブックの作成場所はWorkspaceフォルダでもReposでもどこでも構いません。本ブログではReposにノートブックを作成しています。
key = "Storage Account key"
spark.conf.set("fs.azure.account.key.<account-name>.dfs.core.windows.net",key)
df = spark.read.csv("abfss://<container-name>@<account-name>.dfs.core.windows.net/data.csv",header="true")
df.show()csvファイルの内容が結果に表示されるか確認してみてください。
Storage Accountにprivate endpointを設定する
詳細は省略しますが、以下の点に注意して作成してください。
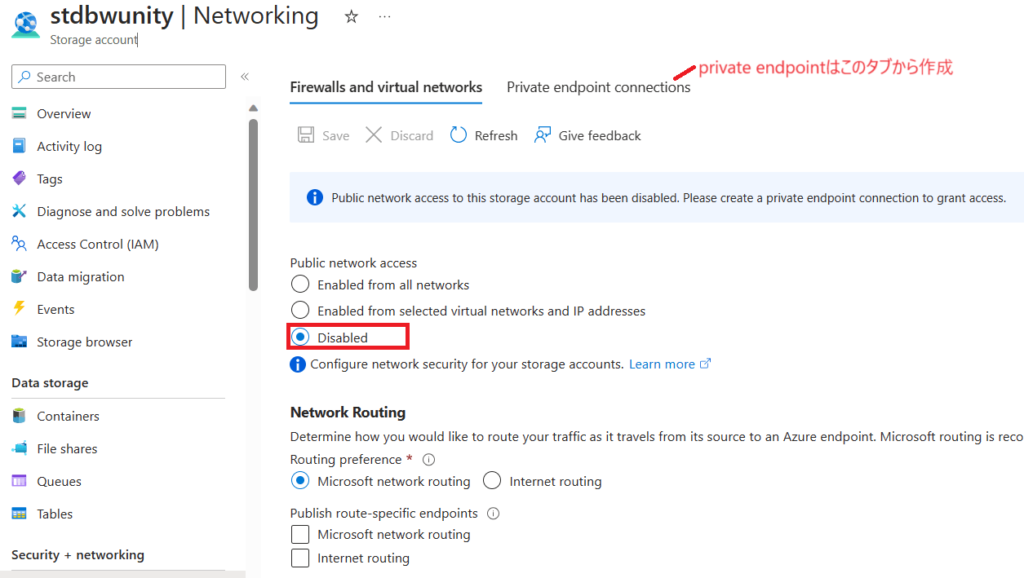
Storage Accountのprivate endpointを作成するときに、ターゲットサブリソースを1つ選択します。(blob、table、queue、file、web、dfs)。ここでは「dfs」を選択します。VNET設定では事前に作成したvnet-endpointsを選択します。サブネットはdefaultサブネットを利用します。それ以外の設定はデフォルトのままで大丈夫です。
またFirewall設定でpublicアクセスを無効化します。
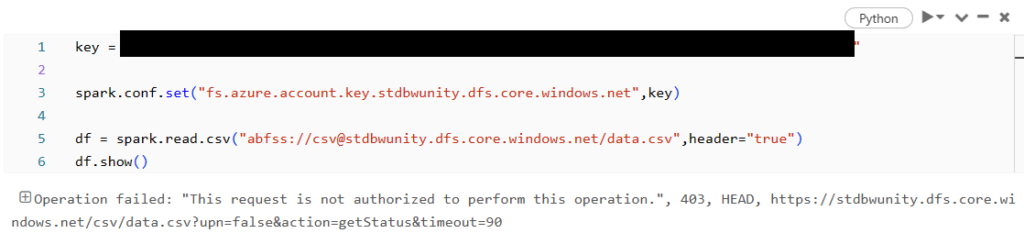
この時点でDatabricksワークスペースからpublic経由でStorageへアクセスできなくなったため、再度ノートブックを実行すると以下のようにエラーになります。
2つのVNETをピアリング
DatabricksワークスペースからprivateでStorage Accountに接続するために2つのVNETをピアリングします。
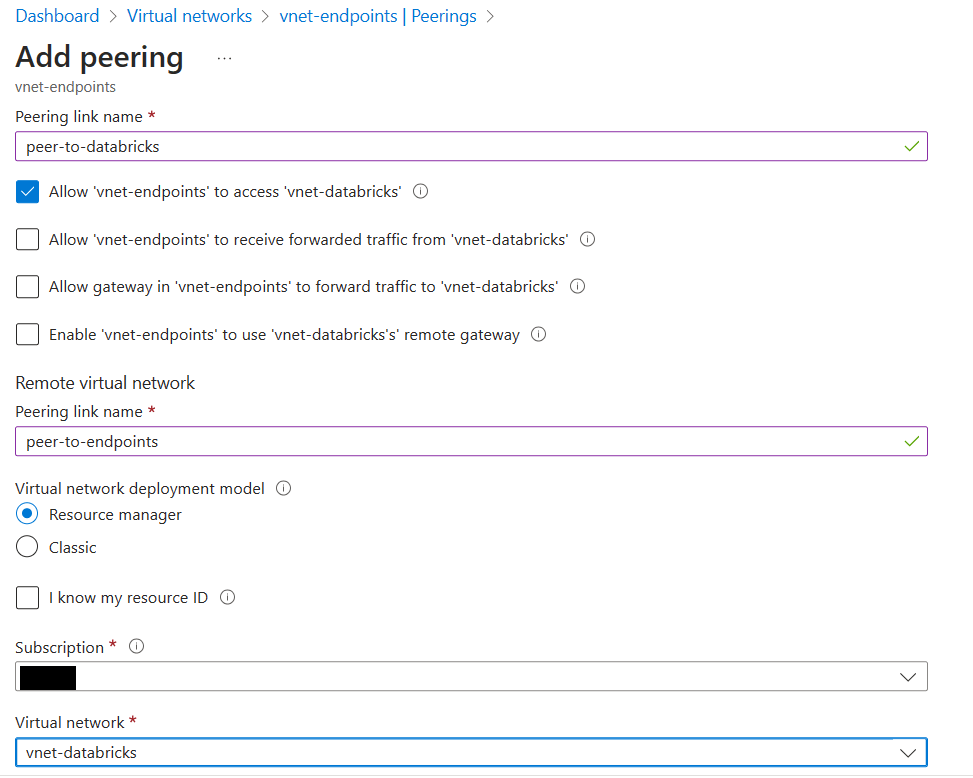
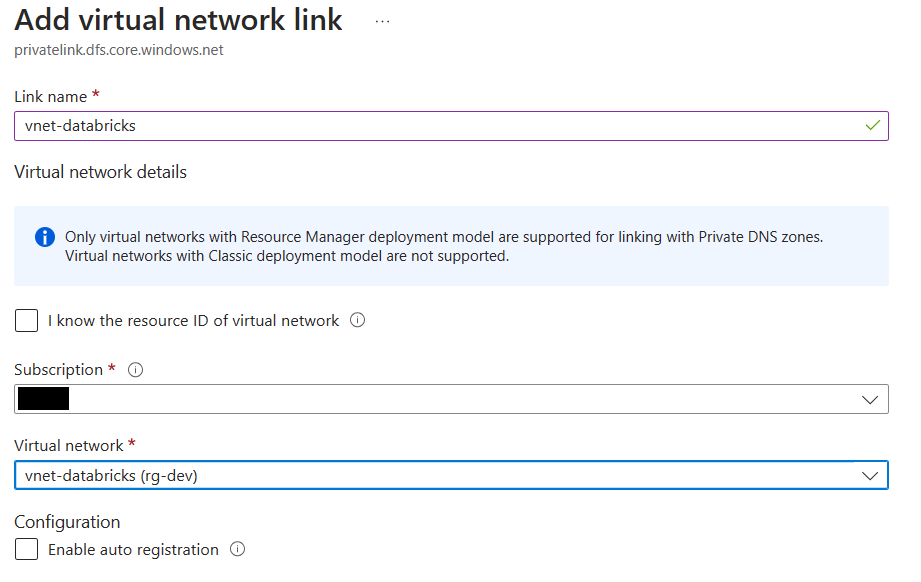
private DNSゾーンをvnet-databricksに関連付ける
ピアリングしたことで経路は準備できました。最後にStorage Accountのprivate endpointのIPアドレスをvnet-databricks内から引くことができるように、private DNZゾーンを紐づけます。private DNSゾーンの設定からvnet-databricksの紐づけを行います。
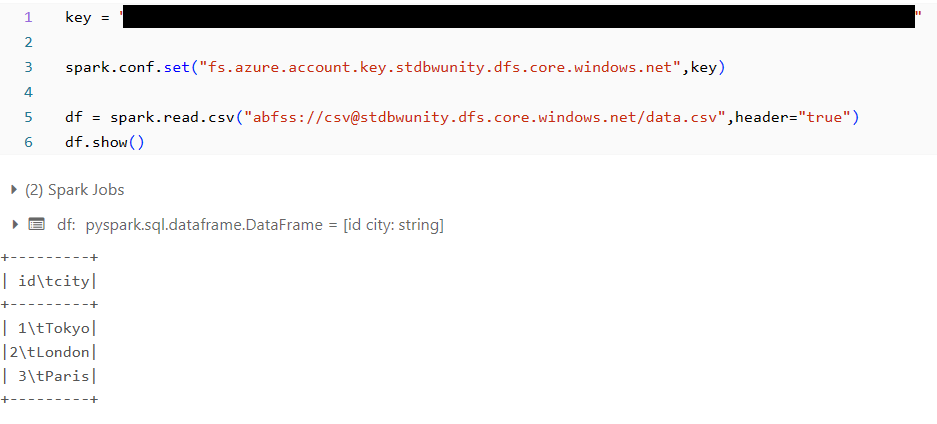
動作確認
これでprivateにStorage Accountにアクセスできるようになったため、問題なくファイルを読み取ることができるようになりました。
MS管理VNET
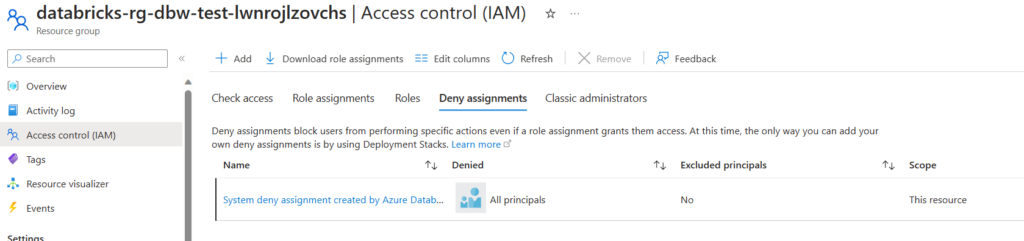
最初は、Databricks用の利用者管理VNETを作成せずに、デフォルトで作成されるMS管理VNETとendpoint用VNETをピアリングすればいいと思っていました。実際ピアリングすることはできます。しかし、MS管理VNETからendpoint用VNETにあるStorageのprivate endpointのDNSを引くためには、private DNSゾーンをMS管理VNETに紐づける必要があります。しかし、紐づけようとすると「System deny assignment created by Azure Databricks」というエラーが発生して紐づけに失敗します。
それもそのはずで、MS管理VNETにはDeny assignmentが設定されています。正確にはMS管理VNETが属しているリソースグループに設定されています。このリソースグループはDatabricks作成時に自動で作成されます。以下のように、一部(*/readなど)を除きほぼすべての操作が禁止されています。
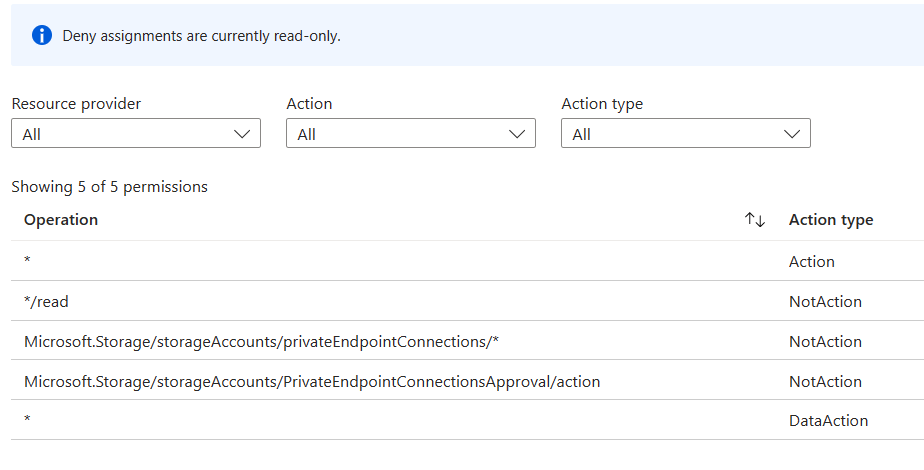
そのためDatabricksからその他のAzureサービスにprivateアクセスするためには、利用者自身でDatabricksを配置するVNETを作成する必要があります。
まとめ
Azure Databricksから様々なAzureサービスにアクセスすることがあると思います。この時Azureサービスにprivate通信するためには、Databricksワークスペースを独自のVNETに配置する必要があることが分かりました。独自VNETに配置するといっても設定は非常に簡単で、VNETを作成しておき、Databricks作成時にその作成したVNETやサブネット名とCIDRを指定するだけです。
今回VNETはDatabricks用とendpoint用の2つを作成しました。設定的には1つのVNETでも作成できます。ただし、役割が明確に異なりますので、Databricks用のVNETはDatabricks専用にしたほうがいいと思います。
コメント